|
|
|
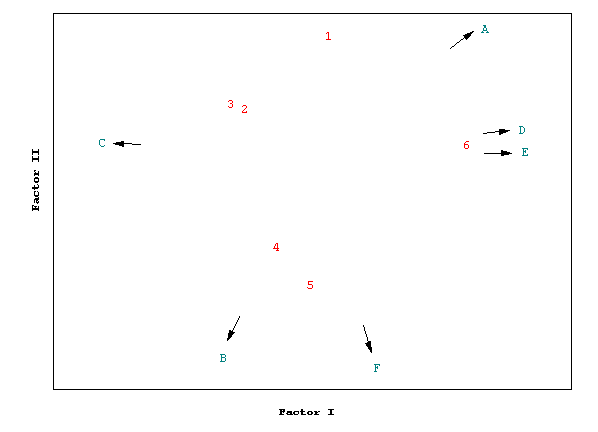
Figure 1, Typical Factor Analysis Perceptual Map (A...F are attributes, 1 ... 6 are the objects) |
Eugene B. Lieb
Custom Decision Support, Inc. (April 1993)
|
Market and value share data contain natural distance relationships between objects and attributes or categories. This note discusses the use of Metric Multidimensional Scaling to construct lower dimensional maps from this type of data that preserve the point-to-point distance relationships among objects and between objects and attributes. |
1. Introduction
There has been a renewal of interest in generating point-to-point maps from marketing research data. Data for mapping consist of a number of objects or observations or respondents evaluated on a number of attributes or categories. Much of this new interest is derived from the potential capability of producing point-to-point maps from cross-tabular categorical data using Correspondence Analysis [1, 2, 3, 6, 9]. However, this interpretation of the Correspondence Maps is still controversial [7]. Traditional mapping techniques, Factor Analysis [8] and Metric Multidimensional Scaling (MMDS) [4, 5], are designed to provide a perspective on multivariant data in a lower number of dimensions than would be needed based on the number of attributes or categories. The attributes are described as vectors.
In Factor Analysis the position of the objects is determined by their relationship with these vectors. In the case of Metric Multidimensional Scaling, the relative position of the objects is derived by an attempt to minimize the distortion in the relative distances between the objects. The meaning of the dimensions is derived in respect to the attribute vectors. Figure 1 shows a typical factor map with the attribute vectors.
|
|
|
Figure 1, Typical Factor Analysis Perceptual Map (A...F are attributes, 1 ... 6 are the objects) |
In many cases there are no natural distance measures between the objects and the attributes and, therefore, it is appropriate to consider them totally separate as is traditionally done in both Factor Analysis and MMDS. In the case of Correspondence Analysis, distance measures are computed based on statistical agreement and scaled to force object and categories on to the same map. This imposes heroic assumptions on the analysis. It should be noted that traditional Correspondence Analysis employs Factor Analysis to produce the final maps. Factor Analysis as opposed to Metric Multidimensional Scaling does not assure the maintenance of relative object positions. This furthermore, raises questions as to the point-to-point interpetation of these maps.
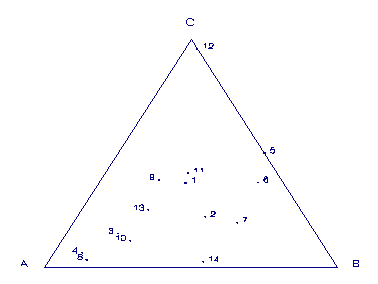
There are classes of data, however, where the distances among objects and between objects and attributes are natural. Market and value share and importance data obtained on constant sum scales fall into this category. This data is normalized for each object. If only three attributes are used, a triangular graph can be used to fully position the objects and attributes. Figure 2 shows a typical triangular plot. This type of graph can be used to display distribution of price ranges where prices are divided between low, medium and high.
|
|
|
Figure 2, Triangular graph displaying the share position of objects (1 ... 12) and attributes (A, B, and C) |
There is no distortion in this plot. The distance between the objects and the vertices represent one minus the share captured by that attribute for that object. All the information contained in the data is captured by the graph. This type of analysis can be extended to four attributes, forming a tetrahedron or "Preference Pyramid" [10] in three dimensions. However, beyond four attributes some method is needed to reduce the dimensionality of the problem. Any reduction in the dimensions usually produces distortion and loss of information. For most practical purpose, it is desired to present the data as a flat, two dimensional, map.
2. Capturing Attribute Positions
As previously noted Metric Multidimensional Scaling (MMDS) is a series of procedures that attempts to reduce the dimensionality of the data in such a way as to maintain the relative distances among the objects. In should be noted, however, that Factor Analysis mapping acts to maximize the captured variance and does not act to conserve the relative distance among objects. The resulting maps using Factor Analysis may not show proper positions in terms of distances. Factor Analysis, however, does present an analytically concise measure of the dimensionality of the data. We typically use it in conjunction with MMDS to confirm the reliability of the mapping. In order to capture the attribute positions, we impose synthetic objects representing the attributions. This represents an identity matrix ( of zeros and ones) placed below the data as shown in table 1.
Attributes
|
Object |
A |
B |
C |
D |
E |
F |
|
1 |
0.508 |
0.032 |
0.281 |
0.027 |
0.072 |
0.081 |
|
2 |
0.025 |
0.068 |
0.739 |
0.023 |
0.041 |
0.104 |
|
3 |
0.031 |
0.130 |
0.710 |
0.022 |
0.021 |
0.086 |
|
4 |
0.049 |
0.216 |
0.531 |
0.017 |
0.017 |
0.170 |
|
5 |
0.058 |
0.322 |
0.356 |
0.014 |
0.089 |
0.162 |
|
6 |
0.407 |
0.005 |
0.000 |
0.227 |
0.219 |
0.142 |
|
... |
... |
... |
... |
... |
... |
... |
|
... |
... |
... |
... |
... |
... |
... |
|
... |
... |
... |
... |
... |
... |
... |
|
A |
1 |
0 |
0 |
0 |
0 |
0 |
|
B |
0 |
1 |
0 |
0 |
0 |
0 |
|
C |
0 |
0 |
1 |
0 |
0 |
0 |
|
D |
0 |
0 |
0 |
1 |
0 |
0 |
|
E |
0 |
0 |
0 |
0 |
1 |
0 |
|
F |
0 |
0 |
0 |
0 |
0 |
1 |
Table 1, Typical Data Matrix for Point-to-Point MMDS Analysis
The resulting MMDS map is shown in Figure 3. The MMDS maps were created using SYSTAT. MMDS is an optimization process which often has multiple local solutions. We have found it necessary to start with an initial configuration with the attributes located around the periphery of the map and the objects in the center.
|
|
|
Figure 3, Two Dimensional Point-to-Point MMDS Map (objects are (1 ... 6) and attributes are A, B, and C) |
As we would expect, the attributes are located around the objects as they do in the lower dimensional cases, the triangular and tetrahedron maps. The closer that the objects are to the attributes the higher the share represented. The closer that the objects are to each other the more similar is the share mix.
3. Distortion
There are two sources of spatial distortion: (1) the distortion of the object positions due to the "flattening" of the space and (2) the imposition of the attribute positions. The distortion comes from any reduction in dimensionality and results in loss of information. Factor Analysis of the data can be used to determine the degree of inherent distortion that can be expected. In our example over 86% of the variance among the objects is captured in two dimensions.
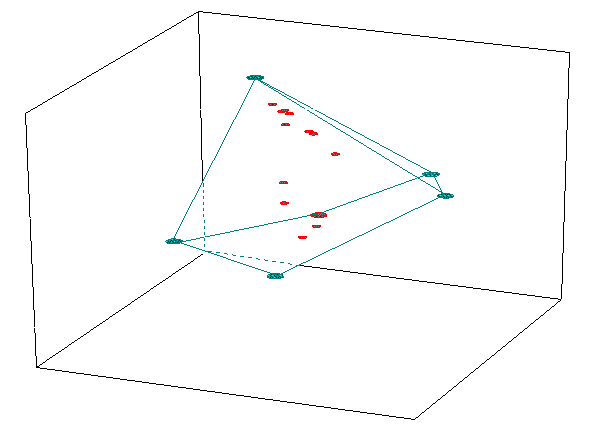
The relative attribute positions are inherently distorted. The use of the identity matrix imposes ideally equal distance among the attributes. This is impossible with the reduced dimensions of the space. As the number of attributes increases, the positions of the attributes have to become more distorted. Fortunately, we are generally not interested in the distances among attributes but distances among objects and between objects and attributes. Unfortunately, the distortion of the attribute positions influence the positions of the objects. This attempt to position the attributes equidistant from each other can be seen in a three dimensional map in figure 4.
|
|
|
Figure 4, Three Dimensional Point-to-Point MMDS Map (objects are small points and attributes are large points) |
The attributes are distributed in a polyhedron around the objects. Though it is not easy to see, the objects form an almost planar configuration. The two dimensional map can be thought of as a projection of the attributes positions onto the planar surface defined by the objects.
The influence of the attributes on the overall configuration can be estimated based on the number of attributes and the number of objects. Multidimensional Scaling works by way of a distance table corresponding to the distance between all objects, between all attributes and between objects and attributes. The distortion should be proportional to the fraction of the total distance measured representing the distances between attributes. We have found that, if the number of attributes is less than half the number of objects, than the distances between the attributes contribute less than 10% of the total variability.
4. Use and Implications
Displaying multivariant data by these maps serves both as an analytical tool, identifying underlying order, and as a means of communicating results. The form of point-to-point maps is particularly useful in communications. The point-vector perceptual maps are difficult for the uninitiated to understand.
We have found that MMDS point-to-point maps are particularly useful with trend or dynamic data. Multivariant trends tend to be complex. The point-to-point maps can simplify both analysis and communications. Figure 5, shows a typical dynamic map.
|
|
|
Figure 5, Dynamic Point-to-Point MMDS Map (arrows connect 5 year object points) |
There is a side benefit in dynamic mapping in that a large numbers of objects are usually involved. This tends to reduce the distortion introduced by the attribute locations. It is important to note that the maps are only approximations of the data. We have found it necessary to refer back to the cross tables for details of what is happening.
References
1. Carroll, J. Douglas and Catherine M. Schafer "Interpoint Distance Comparisons in Correspondence Analysis", Journal of Marketing Research, 23 (1986) pp 271- 280
2. Carroll, J. Douglas, Paul E. Green, and Catherine M. Schaffer, "Comparing Interpoint Distances in Correspondence Analysis: A Clarification", Journal of Marketing Research, 24 (1987) pp 445- 450
3. Carroll, J. Douglas and Paul E. Green "An INDSCAL Based Approach to Multiple Correspondence Analysis", Journal of Marketing Research, 25 (1988) pp 193- 203
4. Green, Paul E. and Frank J. Carmone, Multidimensional Scaling and Related Techniques in Marketing Research, Boston, Alyn and Bacon (1970)
5. Green, Paul E., Abba M. Kriger, and Douglas J. Carroll, "Multidimensional Scaling: A Complementary Approach", Journal of Advertising Research, (1984) pp 21 - 27
6. Greenacre, Michael J., Theory and Applications of Correspondence Analysis, London, Academic Press (1984)
7. Greenacre, Michael J. "The Carroll-Green Schaffer Scaling in Correspondence Analysis: A Theoretical and Empirical Appraisal", Journal of Marketing Research, 26 (1989) pp 358-365
Reply: Carroll, J. Douglas, Paul E. Green, and Catherine M. Schaffer, Journal of Marketing Research, 26 (1989) pp 366 - 369.
8. Harman, Harry H., Modern Factor Analysis, Chicago, University of Chicago Press (1960)
9. Kaciak, E. J. Louviere, "Multiple Correspondence Analysis of Multiple Choice Experiment Data", Journal of Marketing Research, 27 (1990) pp. 455 - 465
10 Wilson, L. O., A. M. Weiss, G. John, "Unbundling of Industrial Systems", Journal of Marketing Research, 27 (1990) pp. 123 - 138